Optimizers
What is an optimizer?
An optimizer is an algorithm that uses two primary inputs; a target function and an initial guess. The optimizer’s job is to figure out which input to the target function will minimise the output of the target function.
Within reliability, the Fitters and ALT_Fitters modules rely heavily on optimizers to find the parameters of the distribution that will minimize the log-likelihood function for the given data set. This process is fundamental to the Maximum Likelihood Estimation (MLE) method of fitting a probability distribution.
There are four optimizers supported by reliability. These are “TNC”, “L-BFGS-B”, “nelder-mead”, and “powell”. All of these optimizers are bound constrained, meaning that the functions within reliability will specify the bounds of the parameters (such as making the parameters greater than zero) and the optimizer will find the optimal solution that is within these bounds. These four optimizers are provided by scipy.
The optimizer can be specified as a string using the “optimizer” argument. For example:
from reliability.Fitters import Fit_Weibull_2P
Fit_Weibull_2P(failures=[1,7,12], optimizer='TNC')
The optimizer that was used is always reported by each of the functions in Fitters and ALT_Fitters. An example of this is shown below on the third line of the output. In the case of Fit_Everything and Fit_Everything_ALT, the optimizer used for each distribution or model is provided in the table of results.
'''
Results from Fit_Weibull_2P (95% CI):
Analysis method: Maximum Likelihood Estimation (MLE)
Optimizer: TNC
Failures / Right censored: 3/0 (0% right censored)
Parameter Point Estimate Standard Error Lower CI Upper CI
Alpha 7.16845 3.33674 2.8788 17.85
Beta 1.29924 0.650074 0.487295 3.46408
Goodness of fit Value
Log-likelihood -8.56608
AICc Insufficient data
BIC 19.3294
AD 3.72489
Why do we need different optimizers?
Each optimizer has various strengths and weaknesses because they work in different ways. Often they will arrive at the same result. Sometimes they will arrive at different results, either because of the very shallow gradient near the minimum, or the non-global minimum they have found. Sometimes they will fail entirely.
There is no single best optimizer for fitting probability distributions so a few options are provided as described below.
Which optimizer should I pick?
You don’t really need to worry about picking an optimizer as the default choice is usually sufficient. If you do want to select your optimizer, you have four to choose from. Most importantly, you should be aware of what the optimizer is doing (minimizing the negative log-likelihood equation by varying the parameters) and understand that optimizers aren’t all the same which can cause different results. If you really need to know the best optimizer then select “best”, otherwise you can just leave the default as None.
There are three behaviours within reliability with respect to the choice of optimizer. These depend on whether the user has specified a specific optimizer (“TNC”, “L-BFGS-B”, “nelder-mead”, “powell”), specified all optimizers (“all” or “best”), or not specified anything (None).
In the case of a specific optimizer being specified, it will be used. If it fails, then the initial guess will be returned with a warning.
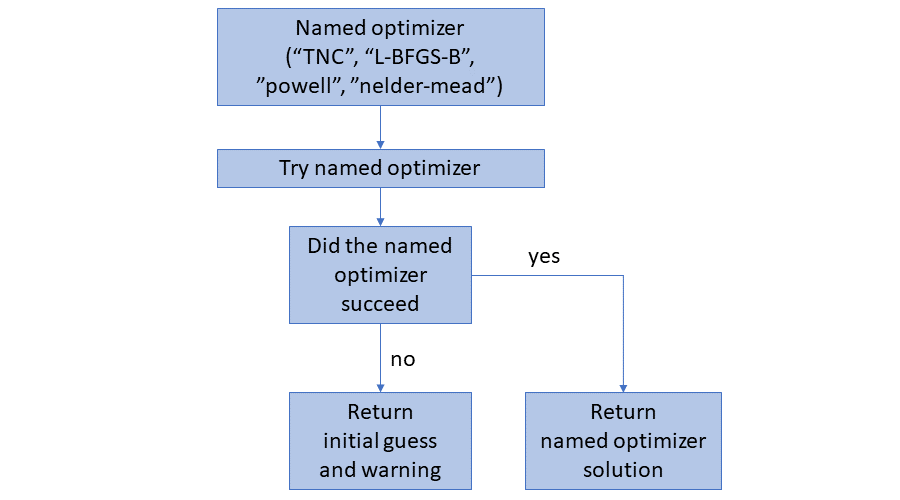
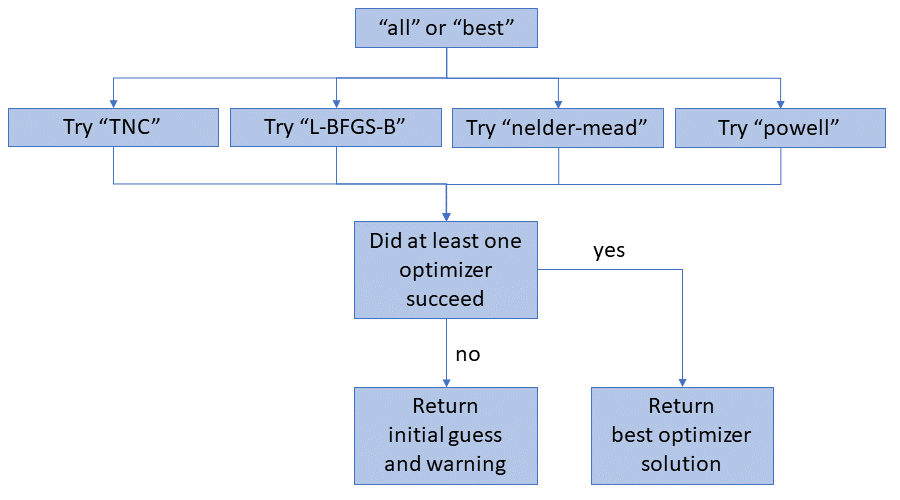
In the case of “best” or “all” being specified, all four of the optimizers will be tried. The results from the best one (based on the lowest log-likelihood it finds) will be returned.
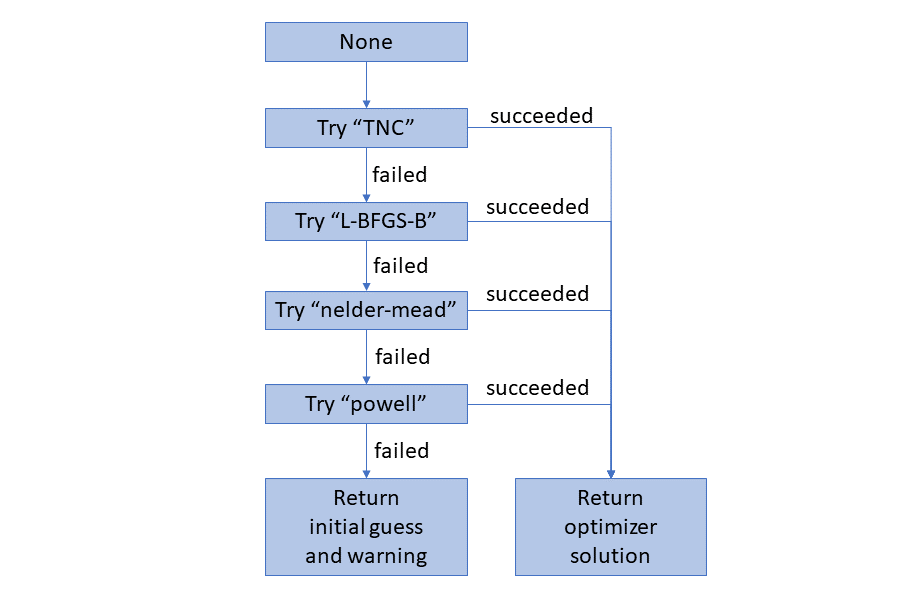
In the case of no optimizer being specified, they will be tried in order of “TNC”, “L-BFGS-B”, “nelder-mead”, “powell”. Once one of them succeeds, the results will be returned and no further optimizers will be run.
Note
For large sample sizes (above 10000) it will take considerable time to run multiple optimizers. In particular, “nelder-mead” and “powell” are much slower than “TNC” and “L-BFGS-B”. For this reason, reliability does not try multiple optimizers unless told to or if the default did not succeed.
Note
There are some rare occasions when the optimizer finds a result (and reports it succeeded) but another optimizer may find a better result. If you always want to be sure that the best result has been found, specify “best” or “all” for the optimizer, and be prepared to wait longer for it to compute if you have a large amount of data. The typical difference between the results of different optimizers which succeeded is very small (around 1e-8 for the log-likelihood) but this is not always the case as the number of parameters in the model increase.