Mixture models
What are mixture models?
Mixture models are a combination of two or more distributions added together to create a distribution that has a shape with more flexibility than a single distribution. Each of the mixture’s components must be multiplied by a proportion, and the sum of all the proportions is equal to 1. The mixture is generally written in terms of the PDF, but since the CDF is the integral (cumulative sum) of the PDF, we can equivalently write the Mixture model in terms of the PDF or CDF. For a mixture model with 2 distributions, the equations are shown below:
\({PDF}_{mixture} = p\times{PDF}_1 + (1-p)\times{PDF}_2\)
\({CDF}_{mixture} = p\times{CDF}_1 + (1-p)\times{CDF}_2\)
\({SF}_{mixture} = 1-{CDF}_{mixture}\)
\({HF}_{mixture} = \frac{{PDF}_{mixture}}{{SF}_{mixture}}\)
\({CHF}_{mixture} = -ln({SF}_{mixture})\)
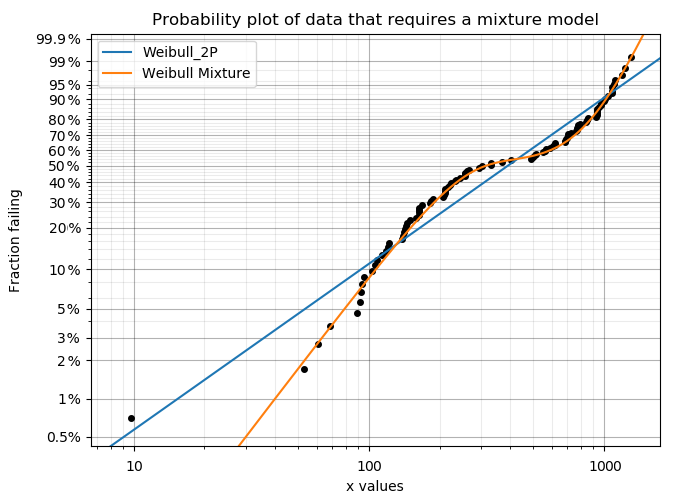
Mixture models are useful when there is more than one failure mode that is generating the failure data. This can be recognised by the shape of the PDF and CDF being outside of what any single distribution can accurately model. On a probability plot, a mixture of failure modes can be identified by bends or S-shapes in the data that you might otherwise expect to be linear. An example of this is shown in the image below. You should not use a mixture model just because it can fit almost anything really well, but you should use a mixture model if you suspect that there are multiple failure modes contributing to the failure data you are observing. To judge whether a mixture model is justified, look at the goodness of fit criterion (AICc or BIC) which penalises the score based on the number of parameters in the model. The closer the goodness of fit criterion is to zero, the better the fit. Using AD or log-likelihood for this check is not appropriate as these goodness of fit criterions do not penalise the score based on the number of parameters in the model and are therefore prone to overfitting.
See also competing risk models for another method of combining distributions using the product of the SF rather than the sum of the CDF.
Creating a mixture model
Within reliability.Distributions is the Mixture_Model. This function accepts an array or list of standard distribution objects created using the reliability.Distributions module (available distributions are Exponential, Weibull, Gumbel, Normal, Lognormal, Loglogistic, Gamma, Beta). There is no limit to the number of components you can add to the mixture, but it is generally preferable to use as few as are required to fit the data appropriately (typically 2 or 3). In addition to the distributions, you can specify the proportions contributed by each distribution in the mixture. These proportions must sum to 1. If not specified the proportions will be set as equal for each component.
As this process is additive for the survival function, and may accept many distributions of different types, the mathematical formulation quickly gets complex. For this reason, the algorithm combines the models numerically rather than empirically so there are no simple formulas for many of the descriptive statistics (mean, median, etc.). Also, the accuracy of the model is dependent on xvals. If the xvals array is small (<100 values) then the answer will be “blocky” and inaccurate. The variable xvals is only accepted for PDF, CDF, SF, HF, and CHF. The other methods (like random samples) use the default xvals for maximum accuracy. The default number of values generated when xvals is not given is 1000. Consider this carefully when specifying xvals in order to avoid inaccuracies in the results.
API Reference
For inputs and outputs see the API reference.
Example 1
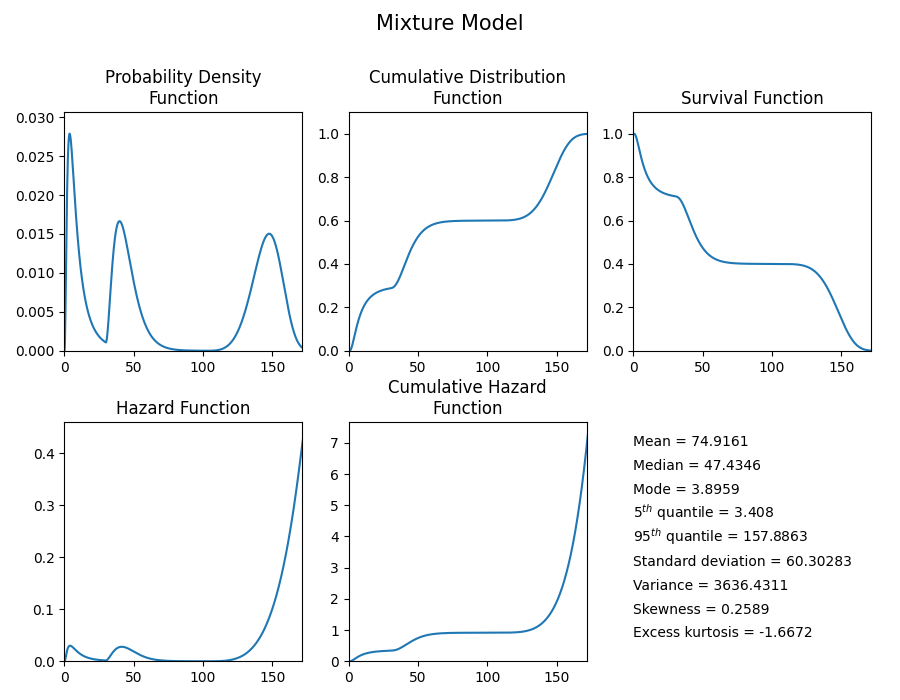
The following example shows how the Mixture_Model object can be created, visualised and used.
from reliability.Distributions import Lognormal_Distribution, Gamma_Distribution, Weibull_Distribution, Mixture_Model
import matplotlib.pyplot as plt
# create the mixture model
d1 = Lognormal_Distribution(mu=2, sigma=0.8)
d2 = Weibull_Distribution(alpha=50, beta=5, gamma=100)
d3 = Gamma_Distribution(alpha=5, beta=3, gamma=30)
mixture_model = Mixture_Model(distributions=[d1, d2, d3], proportions=[0.3, 0.4, 0.3])
# plot the 5 functions using the plot() function
mixture_model.plot()
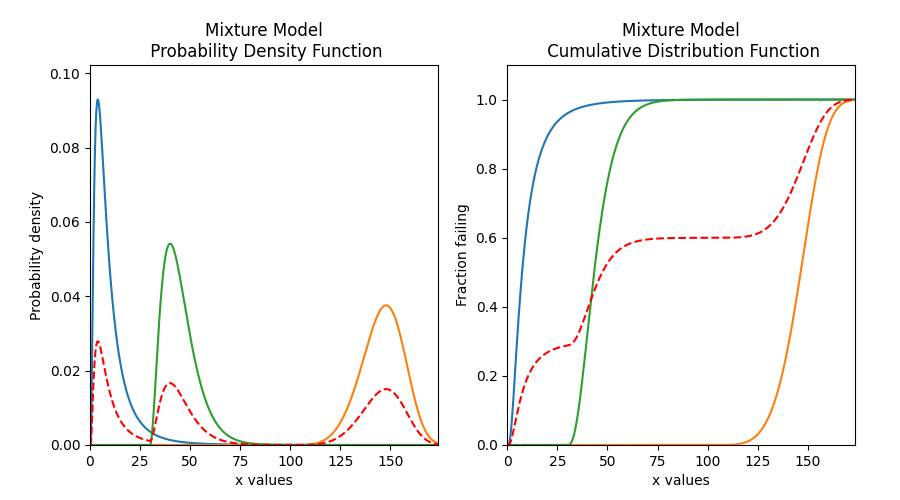
# plot the PDF and CDF
plot_components = True # this plots the component distributions. Default is False
plt.figure(figsize=(9, 5))
plt.subplot(121)
mixture_model.PDF(plot_components=plot_components, color='red', linestyle='--')
plt.subplot(122)
mixture_model.CDF(plot_components=plot_components, color='red', linestyle='--')
plt.subplots_adjust(left=0.1, right=0.95)
plt.show()
# extract the mean of the distribution
print('The mean of the distribution is:', mixture_model.mean)
'''
The mean of the distribution is: 74.91607709895453
'''
Fitting a mixture model
Within reliability.Fitters is Fit_Weibull_Mixture. This function will fit a Weibull Mixture Model consisting of 2 x Weibull_2P distributions (this does not fit the gamma parameter). Just as with all of the other distributions in reliability.Fitters, right censoring is supported, though care should be taken to ensure that there still appears to be two groups when plotting only the failure data. A second group cannot be made from a mostly or totally censored set of samples.
Whilst some failure modes may not be fitted as well by a Weibull distribution as they may be by another distribution, it is unlikely that a mixture of data from two distributions (particularly if they are overlapping) will be fitted noticeably better by other types of mixtures than would be achieved by a Weibull mixture. For this reason, other types of mixtures are not implemented.
API Reference
For inputs and outputs see the API reference.
Example 2
In this example, we will create some data using two Weibull distributions and then combine the data using np.hstack. We will then fit the Weibull mixture model to the combined data and will print the results and show the plot. As the input data is made up of 40% from the first group, we expect the proportion to be around 0.4.
from reliability.Fitters import Fit_Weibull_Mixture
from reliability.Distributions import Weibull_Distribution
from reliability.Other_functions import histogram
import numpy as np
import matplotlib.pyplot as plt
# create some failures from two distributions
group_1 = Weibull_Distribution(alpha=10, beta=3).random_samples(40, seed=2)
group_2 = Weibull_Distribution(alpha=40, beta=4).random_samples(60, seed=2)
all_data = np.hstack([group_1, group_2]) # combine the data
results = Fit_Weibull_Mixture(failures=all_data) #fit the mixture model
# this section is to visualise the histogram with PDF and CDF
# it is not part of the default output from the Fitter
plt.figure(figsize=(9, 5))
plt.subplot(121)
histogram(all_data)
results.distribution.PDF()
plt.subplot(122)
histogram(all_data, cumulative=True)
results.distribution.CDF()
plt.show()
'''
Results from Fit_Weibull_Mixture (95% CI):
Analysis method: Maximum Likelihood Estimation (MLE)
Optimizer: TNC
Failures / Right censored: 100/0 (0% right censored)
Parameter Point Estimate Standard Error Lower CI Upper CI
Alpha 1 8.65511 0.393835 7.91663 9.46248
Beta 1 3.91197 0.509776 3.03021 5.0503
Alpha 2 38.1103 1.41075 35.4431 40.9781
Beta 2 3.82192 0.421385 3.07916 4.74385
Proportion 1 0.388491 0.0502663 0.295595 0.490263
Goodness of fit Value
Log-likelihood -375.991
AICc 762.619
BIC 775.007
AD 0.418649
'''
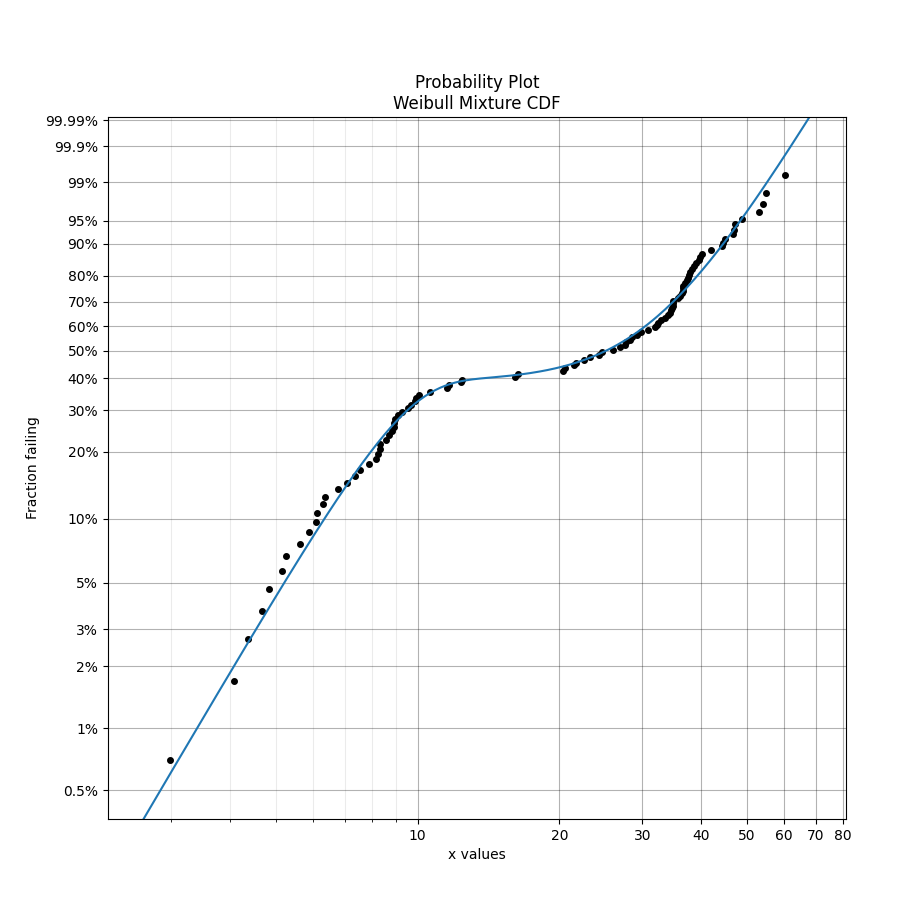
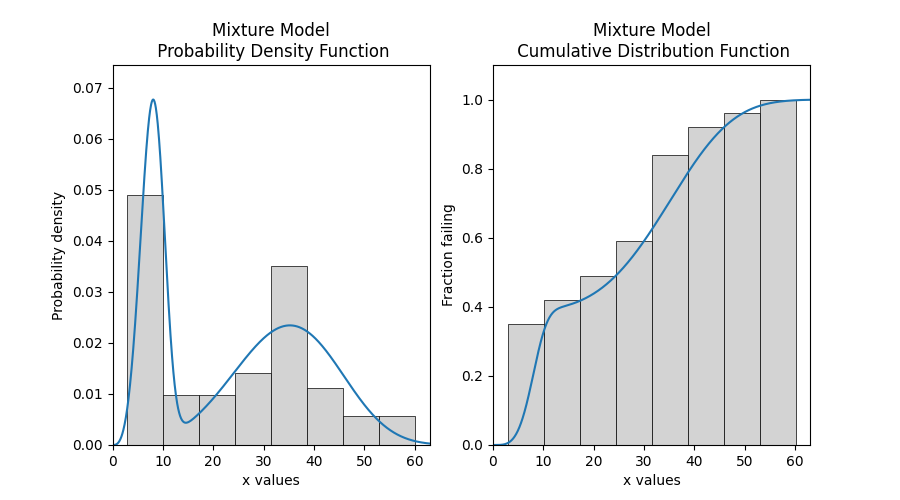
Example 3
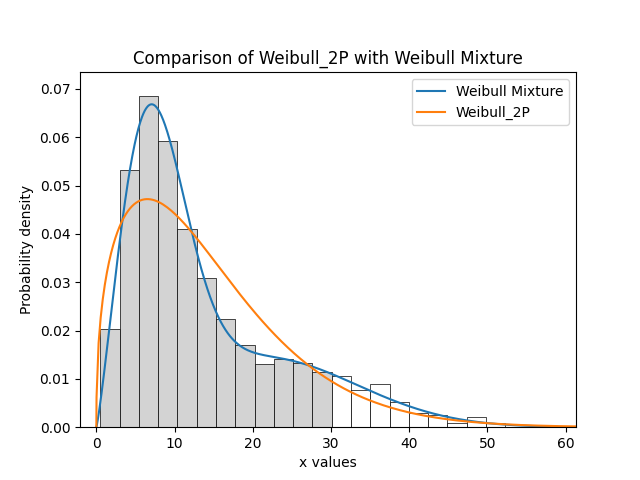
In this example, we will compare how well the Weibull Mixture performs vs a single Weibull_2P. Firstly, we generate some data from two Weibull distributions, combine the data, and right censor it above our chosen threshold. Next, we will fit the Mixture and Weibull_2P distributions. Then we will visualise the histogram and PDF of the fitted mixture model and Weibull_2P distributions. The goodness of fit measure is used to check whether the mixture model is really a much better fit than a single Weibull_2P distribution (which it is due to the lower BIC).
from reliability.Fitters import Fit_Weibull_Mixture, Fit_Weibull_2P
from reliability.Distributions import Weibull_Distribution
from reliability.Other_functions import histogram, make_right_censored_data
import numpy as np
import matplotlib.pyplot as plt
# create some failures and right censored data
group_1 = Weibull_Distribution(alpha=10, beta=2).random_samples(700, seed=2)
group_2 = Weibull_Distribution(alpha=30, beta=3).random_samples(300, seed=2)
all_data = np.hstack([group_1, group_2])
data = make_right_censored_data(all_data, threshold=30)
# fit the Weibull Mixture and Weibull_2P
mixture = Fit_Weibull_Mixture(failures=data.failures, right_censored=data.right_censored, show_probability_plot=False, print_results=False)
single = Fit_Weibull_2P(failures=data.failures, right_censored=data.right_censored, show_probability_plot=False, print_results=False)
print('Weibull_Mixture BIC:', mixture.BIC, '\nWeibull_2P BIC:', single.BIC) # print the goodness of fit measure
# plot the Mixture and Weibull_2P
histogram(all_data, white_above=30)
mixture.distribution.PDF(label='Weibull Mixture')
single.distribution.PDF(label='Weibull_2P')
plt.title('Comparison of Weibull_2P with Weibull Mixture')
plt.legend()
plt.show()
'''
Weibull_Mixture BIC: 6431.578404076784
Weibull_2P BIC: 6511.511759597337
'''